New – Amazon Elasticsearch Service | AWS Official Blog
Amazon Elasticsearch Service | Product Details
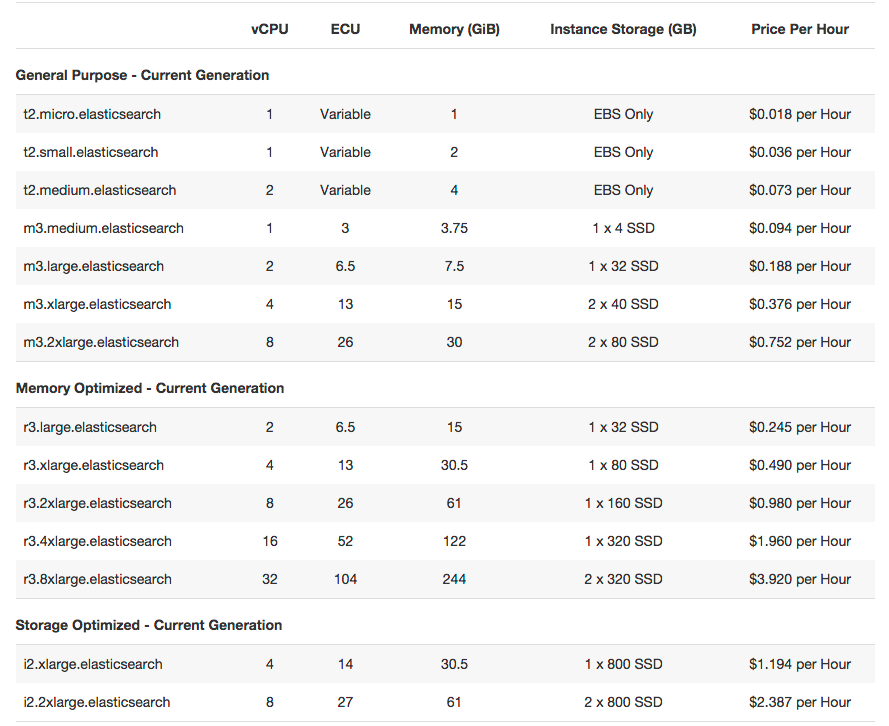
Amazon Elasticsearch Service | Pricing
Key Features
Set-up & Configuration from AWS Management Console or API
With a few clicks, you can create Amazon Elasticsearch domains using the domain creation wizard in the console. Each domain is an Elasticsearch cluster in the cloud with the compute and storage resources you specify. You can also create your domains by a making a single Amazon Elasticsearch Service API call through the AWS Command Line Interface (CLI) or the AWS SDK. While creating a new domain you can specify the number of instances, instance types, and storage options. You can also modify or delete existing domains at any time.
Flexible Storage Options
You can choose between local on-instance storage or Amazon EBS volumes to store your Elasticsearch indices. You can specify the size of the Amazon EBS volume to be allocated to the domain and the volume type - Magnetic, General Purpose, or Provisioned IOPS. You can also modify the storage options after domain creation as needed.
Security and Auditing
Amazon Elasticsearch Service lets you configure access policies for the domain end points using AWS Identity and Access Management (IAM). IAM policies allow your applications running on AWS or outside AWS to access your domain securely. IAM policies can be set up to provide fine-grained access control to the control plane API for operations like creating and scaling domains and data plane API for operations like uploading documents and executing queries. In addition, you can monitor and audit your domain with AWS CloudTrail, a web service that records AWS API calls for your account and delivers log files to you. The AWS API call history produced by AWS CloudTrail enables security analysis, resource change tracking, and compliance auditing.
Support for Logstash and Kibana
Amazon Elasticsearch Service supports integration with Logstash, an open-source data pipeline that helps you process logs and other event data. You can set up your Amazon Elasticsearch domain as the backend store for all logs coming through your Logstash implementation to easily ingest structured and unstructured data from a variety of sources. Amazon Elasticsearch Service also includes built-in support for Kibana, an open-source analytics and visualization platform that helps you get a better understanding of your data. Kibana version 3 and version 4 are automatically deployed with your Amazon Elasticsearch domain.
Direct Access to Elasticsearch API
Amazon Elasticsearch Service gives you direct access to the Elasticsearch APIs to load, query and analyze data, and manage indices.
Scaling Options
You can add or remove instances, and easily modify Amazon EBS volumes to accommodate data growth. You can write a few lines of code that will monitor the state of your domain through Amazon CloudWatch metrics and call the Amazon Elasticsearch Service API to scale your domain up or down based on thresholds you set. The service will execute the scaling without any downtime.
Set-up for High Availability
You can configure your Amazon Elasticsearch domains for high availability by enabling the Zone Awareness option either at domain creation time or by modifying a live domain. When Zone Awareness is enabled, Amazon Elasticsearch Service will distribute the instances supporting the domain across two different availability zones. Then, if you enable replicas in Elasticsearch, the instances are automatically distributed in such a way as to deliver cross-zone replication.
Plug-in Support
Amazon Elasticsearch Service comes prepackaged with a several plugins available from the Elasticsearch community including, Kibana 3, Kibana 4, jetty, cloud-aws, kuromoji, and icu. Plug-ins are automatically deployed and managed for you.
Data Durability
You can build data durability for your Amazon Elasticsearch domain through automated and manual snapshots. You can use snapshots to recover your domain with preloaded data or to create a new domain with preloaded data. Snapshots are stored in Amazon S3, which is a secure, durable, highly-scalable object storage. By default, Amazon Elasticsearch Service will automatically create daily snapshots of each domain. There is no additional charge for the automated daily snapshots. In addition, you can use the Elasticsearch snapshot APIs to create additional manual snapshots. The manual snapshots are stored in Amazon S3 and will incur normal Amazon S3 usage charges.
Monitor Domain Performance
Amazon Elasticsearch Service exposes several performance metrics through Amazon CloudWatch including number of instances, domain health, searchable documents, Amazon EBS metrics (if applicable), CPU, memory and disk utilization for data and master nodes. You can use these metrics to monitor the health of your domain and take any necessary actions such as scaling.
Pay-as-you-go Pricing
With Amazon Elasticsearch Service, you pay only for the compute and storage resources you use. There are no minimum fees or upfront commitments. You don’t need a team of Elasticsearch experts dedicated to provisioning, monitoring, and managing the infrastructure. As a result, your total costs of operating Elasticsearch goes down even at large scale.